
TS
zoyadithya23077
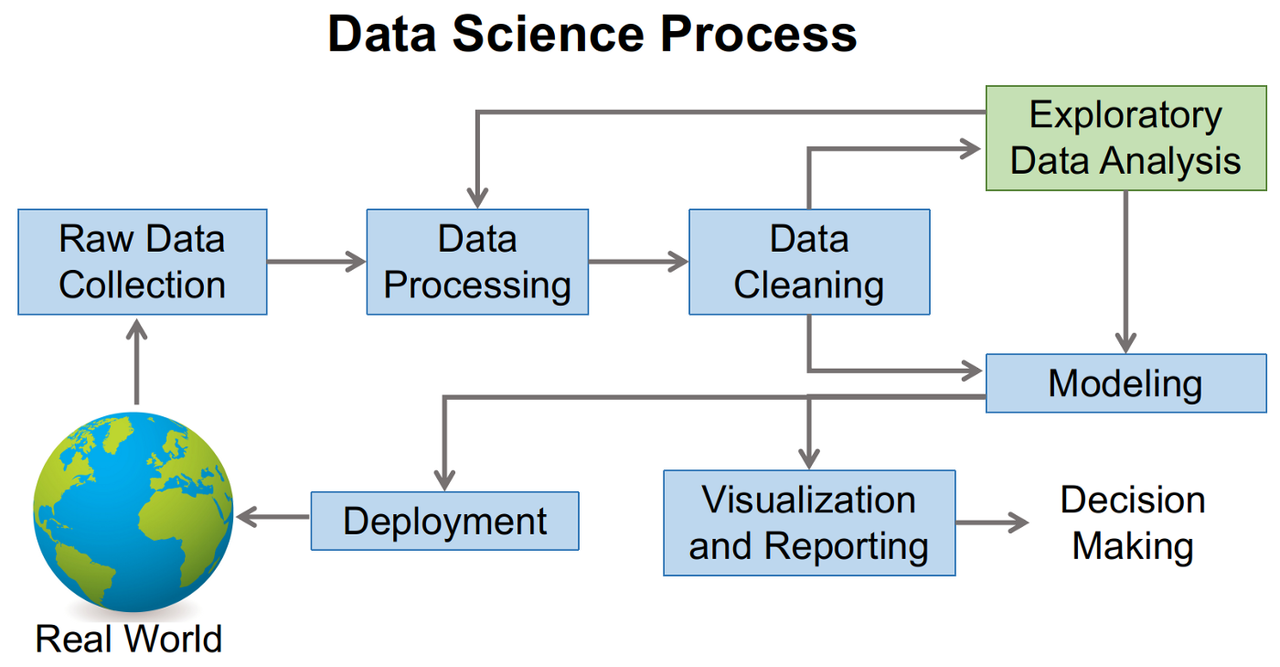
What is Exploratory Data Analysis in the Data Science Process?
EDA's primary goal is to encourage data analysis before making any assumptions. Finding obvious mistakes, understanding data patterns, identifying outliers or unusual occurrences, and figuring out fascinating relationships between the variables can all be helped by it.
Data scientists can use exploratory analysis to ensure the findings are reliable and relevant to any desired business outcomes and goals. EDA assists stakeholders by assuring them that they are posing the right questions. Standard deviations, categorical variables, and confidence intervals are all topics that EDA can help with. After it is finished and concluded, EDA's features can then be used for more complex data analysis or modeling, including machine learning.
Exploratory Data Analysis Techniques
The following specific statistical techniques and operations are possible with EDA tools:
* Techniques like clustering and dimension reduction assist in producing graphical representations of high-dimensional data with numerous variables.
* Summary statistics are shown along with a univariate visualization of each field in the raw dataset. Using bivariate visualizations and summary statistics, you can evaluate the relationship between each variable in the dataset and the target variable you're interested in.
* Multivariate visualizations for locating and understanding relationships between various data fields
* K-means Unsupervised learning uses the clustering technique known as clustering, in which data points are divided into K groups, or the number of clusters, according to how far they are from the centroid of each group. The data points that fall into the same category are those closest to a given centroid. Market segmentation, pattern recognition, and image compression frequently use K-means clustering. For detailed information, head to the machine learning course in Pune.
* To predict outcomes, predictive models like linear regression use statistics and data.
Different kinds of exploratory data analysis
EDA can be categorized into four categories:
1. Single-variate non-graphical
This is the most basic type of data analysis because only one variable is present in the data. It doesn't deal with causes or relationships because it only has one variable. Univariate analysis' primary goals are to describe the data and identify any patterns that may be present.
2. Single-variable graphics
Non-graphical approaches give a partial picture of the data. As a result, graphic techniques are needed. Typical examples of univariate graphics are:
The distribution's shape and data values are displayed in stem-and-leaf plots. The frequency (count) or proportion (count/total count) of cases for a range of values is represented by each bar in a histogram, a bar plot. Box plots graphically represent the minimum, first quartile, median, third quartile, and maximum five-number summary.
3. Non-graphical multivariate data
Multivariate data is made up of multiple variables. Cross-tabulation or statistics are typically used in multivariate non-graphical EDA techniques to show the relationship between two or more data variables.
4. Graphical representations
Multivariate data show the connections between two or more sets of data. The most common type of graph is a grouped bar plot or bar chart, where each group corresponds to a particular level of one of the variables and each bar within a group of a specific level of the other variable.
Tools for Exploratory Data Analysis
The following are some of the most popular data science tools used to develop an EDA:
1. Python
An interpreted, object-oriented, dynamically semantic programming language. Due to its high-level, built-in data structures, dynamic typing, and dynamic binding, it is very appealing for both uses as a scripting or glue language to connect existing components and for rapid application development. It is critical to identify missing values in a data set using Python and EDA to decide how to handle missing values for machine learning.
2. R
This open-source programming language and free software environment for statistical computing and graphics are supported by the R Foundation for Statistical Computing. When creating statistical observations and data analysis, statisticians in data science frequently use the R language.
Conclusion
You first understood the purpose and value of exploratory data analysis in this tutorial. After seeing the steps needed to perform exploratory data analysis, you finally used data from market analysis to carry out all the steps on various types of data.
We hope this clarifies the process of exploratory data analysis. Check out the trending data science course in Pune to learn more about deep learning and machine learning techniques. On the other hand, if you have any questions about this Exploratory Data Analysis tutorial, feel free to leave a comment below.
0
209
0

Guest
Tulis komentar menarik atau mention replykgpt untuk ngobrol seru
Mari bergabung, dapatkan informasi dan teman baru!
Education
22.5KThread•13.6KAnggota
Guest
Tulis komentar menarik atau mention replykgpt untuk ngobrol seru